Aim
Fine-tune huggingface’s distilbert for squad Q&A on Azure.
Context
Recently, I’ve been finding out what closed domain Q&A machines are available. To date I’ve tried out Google’s Bert model on some of the examples from squad with the help of the deeppavlov, and also tools provided by huggingface. Cursory conclusions: Bert’s cool, and it answers questions pretty well but ultimately it’s very slow, at least on my laptop.
Proposition: There are smaller Bert based models - maybe I could try one of these?
The blog post Introducing Distilbert has an overview of the method they use. I have yet to get my head around what distillation is at all.
However, I think they are saying they distilled fine-tuned bert,
rather than fine-tuned distilled bert.
Previously, I have attempted the obvious/naive/dumb thing of just plugging in the model entitled distilbert-base-uncased-distilled-squad
(listed here)into a Q&A test programme.
(Obviously also modifying the code where it seemed necessary to accommodate this model.)
The results I got were garbage.
Perhaps I should ask them at some point…
These general purpose language models come with additional heads for different endcase uses, and require fine-tuning with a specific head on. So, in the meantime, let’s fine-tune the distilbert model. There are instructions here. Is it really as easy as that? Install some programs and run a command. I am so skeptical. Let’s find out!
I have begun running it on my laptop but it’s slow. No surprises there, but it was good to check that it at least runs. I’m going to leave it running for now.
Why Azure?
I know very little about cloud service offerings and I’ve never knowingly used a GPU. Not too much thought went into this. Other options would be Google’s GCE and Amazon’s AWS. I’ve skim read a few blog posts comparing these.
Azure has a free trial account, by which I mean they don’t ask for your card details upfront. I think this is the same on GCE, but not with AWS. You hear stories that it’s easy to accidentally run up charges for services you aren’t even aware of - something best avoided.
I have previously got stuck with example notebooks on GCE that wouldn’t run. Finally, Azure came up in conversation yesterday, and that swung it.
Introduction to ML in Azure
I’m using this tutorial.
First you create a MachineLearning Workspace. I assume this creates some containerized environment in which to work… Ok. I really didn’t get very far with this. The tutorial points you to the Machine Learning Service. After that, they go on and on about notebooks - I have never found a love for notebooks. Hmmm. How do you just get a machine? I’m going off piste…
In the machine learning service…
I set up a ‘compute > training cluster’: an ubuntu VM with GPU access. I chose something basic - 12 CPUs and 2 GPUs. In the advanced options I added admin with ssh access and added a key.
Once established, the manage tab displays compute details. On the ‘Nodes’ tab is the public IP (pip) and port. Using this I can ssh.
$ssh waalge@52.142.127.72 -p 50000
The authenticity of host '[52.142.127.72]:50000 ([52.142.127.72]:50000)' can't be established.
ECDSA key fingerprint is SHA256:KnqtVui/8qIyTDk5i3ogtz4V0hysVk8Dzxz5hQDCjkE.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '[52.142.127.72]:50000' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 16.04.6 LTS (GNU/Linux 4.15.0-1057-azure x86_64)And we’re in! However we are in shell. To get a more useable terminal environment, use:
bashOk, checking out the VM. Spec?
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Thread(s) per core: 1
Core(s) per socket: 12
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2690 v3 @ 2.60GHz
Stepping: 2
CPU MHz: 2596.991
BogoMIPS: 5193.98
Hypervisor vendor: Microsoft
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 30720K
NUMA node0 CPU(s): 0-11
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm invpcid_single pti fsgsbase bmi1 avx2 smep bmi2 erms invpcid xsaveopt md_clearHardware?
$ sudo lshw -C display
*-display
description: VGA compatible controller
product: Hyper-V virtual VGA
vendor: Microsoft Corporation
physical id: 8
bus info: pci@0000:00:08.0
version: 00
width: 32 bits
clock: 33MHz
capabilities: vga_controller bus_master rom
configuration: driver=hyperv_fb latency=0
resources: irq:11 memory:f8000000-fbffffff memory:c0000-dffff
*-display:0
description: 3D controller
product: GK210GL [Tesla K80]
vendor: NVIDIA Corporation
physical id: 2
bus info: pci@0d2f:00:00.0
version: a1
width: 64 bits
clock: 33MHz
capabilities: pm msi pciexpress bus_master cap_list
configuration: driver=nvidia latency=0
resources: iomemory:100-ff iomemory:140-13f irq:24 memory:41000000-41ffffff memory:1000000000-13ffffffff memory:1400000000-1401ffffff
*-display:1
description: 3D controller
product: GK210GL [Tesla K80]
vendor: NVIDIA Corporation
physical id: 0
bus info: pci@31ee:00:00.0
version: a1
width: 64 bits
clock: 33MHz
capabilities: pm msi pciexpress bus_master cap_list
configuration: driver=nvidia latency=0
resources: iomemory:180-17f iomemory:1c0-1bf irq:25 memory:42000000-42ffffff memory:1800000000-1bffffffff memory:1c00000000-1c01ffffffTwo Tesla K80s. Cool.
Python?
$ python3 --version
Python 3.5.2Really?!
$ sudo apt install software-properties-common && \
sudo add-apt-repository ppa:deadsnakes/ppa && \
sudo apt update && \
sudo apt install python3.7 python3.7-dev && \
python3.7
Python 3.7.5 (default, Oct 15 2019, 21:38:37) Phew! (Note: Remapping python3 to python3.7 caused a load of problems. We’ll just live with having to type python3.7 into everything.)
Get pip!
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3.7 get-pip.py --userGit and vim are preinstalled (although vim7.4). What else could one need??
Install python modules
pip install --user torch transformers tensorboardXThe last of these is found in the transformers git repo examples/requirements.txt.
Pull the git repository
git clone https://github.com/huggingface/transformers.git(Then pip install --user -r transformers/examples/requirements.txt should go install any remaining modules should these change in future.
One can of course use pip to install this local copy of transformers.)
Get the squad data and evaluation script
mkdir squad_data &&
curl https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json -o squad_data/train-v1.1.json &
curl https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json -o squad_data/dev-v1.1.json &The instructions also refer to an evaluation script here but I think it has one. In any case, you can curl that too.
curl https://github.com/allenai/bi-att-flow/blob/master/squad/evaluate-v1.1.py -o squad_data/evaluate-v1.1.py Make a debug directory
mkdir debug I wrote a script which just prints the squad instructions.
The command is a modified form of one found on the transformers examples page.
I found it annoying to try to edit that command in the terminal.
In the script vim make_cmd.py, I had the following
import os, subprocess
PYTHON = "python3.7"
PWD = os.getcwd()
SQUAD_DIR = os.path.join(PWD, "squad_data")
DEBUG_DIR = os.path.join(PWD, "debug")
MODEL = "distilbert-base-uncased"
RUN_SQUAD = os.path.join(PWD, "transformers/examples/run_squad.py")
cmd = [
PYTHON, RUN_SQUAD,
"--model_type", "distilbert",
"--model_name_or_path", MODEL,
"--do_train",
"--do_eval",
"--do_lower_case",
"--train_file", os.path.join(SQUAD_DIR, "train-v1.1.json"),
"--predict_file", os.path.join(SQUAD_DIR,"dev-v1.1.json"),
"--per_gpu_train_batch_size", "12",
"--learning_rate", "3e-5",
"--num_train_epochs", "2.0",
"--max_seq_length", "384",
"--doc_stride", "128",
"--output_dir", DEBUG_DIR,
]
print(" ".join(cmd))The structure of my home is as follows:
$ tree -L 1
.
├── debug
├── get-pip.py
├── make_cmd.py
├── squad_data
└── transformers(I had to install tree to run this.)
To print the command
$python3.7 make_cmd.pyOr to just run it
$ $(python3.7 make_cmd.py)I started running this again in tmux so I could detach if needed.
The live stream…
Status >30 mins
The process has been running for about 30 minutes. It’s using two cores pretty solidly (htop was preinstalled). I would like to see if it’s using a GPU. How about vntop? Following the instructions there
sudo apt install cmake libncurses5-dev libncursesw5-devAnd their build instructions
git clone https://github.com/Syllo/nvtop.git
mkdir -p nvtop/build && cd nvtop/build
cmake ..
# If it errors with "Could NOT find NVML (missing: NVML_INCLUDE_DIRS)"
# try the following command instead, otherwise skip to the build with make.
cmake .. -DNVML_RETRIEVE_HEADER_ONLINE=True
make
make install # You may need sufficient permission for that (root)Both comments were apt in my case.
This has a nice pretty htop-like display, as advertised. It seems that both GPUs are being employed. Problem: I couldn’t copy the text output to here.
How about the python module gpustat:
$ pip install --user gpustatWorks a charm:
$gpustat
20088bdd3bdb48328074d70f8e18c6d6000000 Thu Nov 28 19:49:51 2019 418.87.00
[0] Tesla K80 | 83'C, 94 % | 5732 / 11441 MB | waalge(5719M)
[1] Tesla K80 | 58'C, 55 % | 4748 / 11441 MB | waalge(4735M)Status > 1hour
An hour has past and the run on azure has completed 1 of the 2 epochs involved in the training.
I actually began running the same program on my laptop earlier today. The laptop suggests it will take 26 hours to complete the same task - it’s still on the first epoch.
Just looking for some time estimates of comparable training exercises. The Introducing distilbert blog post is doing something else. In any case there is no mention of the training cost.
On the huggingface transformers docs, under the examples (here), they say that they fine-tuned little (normal) Bert on a V100 in 24minutes. V100s are quite an impressive step up from the K80, (according to these guys). The program on azure is estimating 2.5 hours, which sounds like reasonable.
Here’s a screenshot! (Go to source to zoom in.)
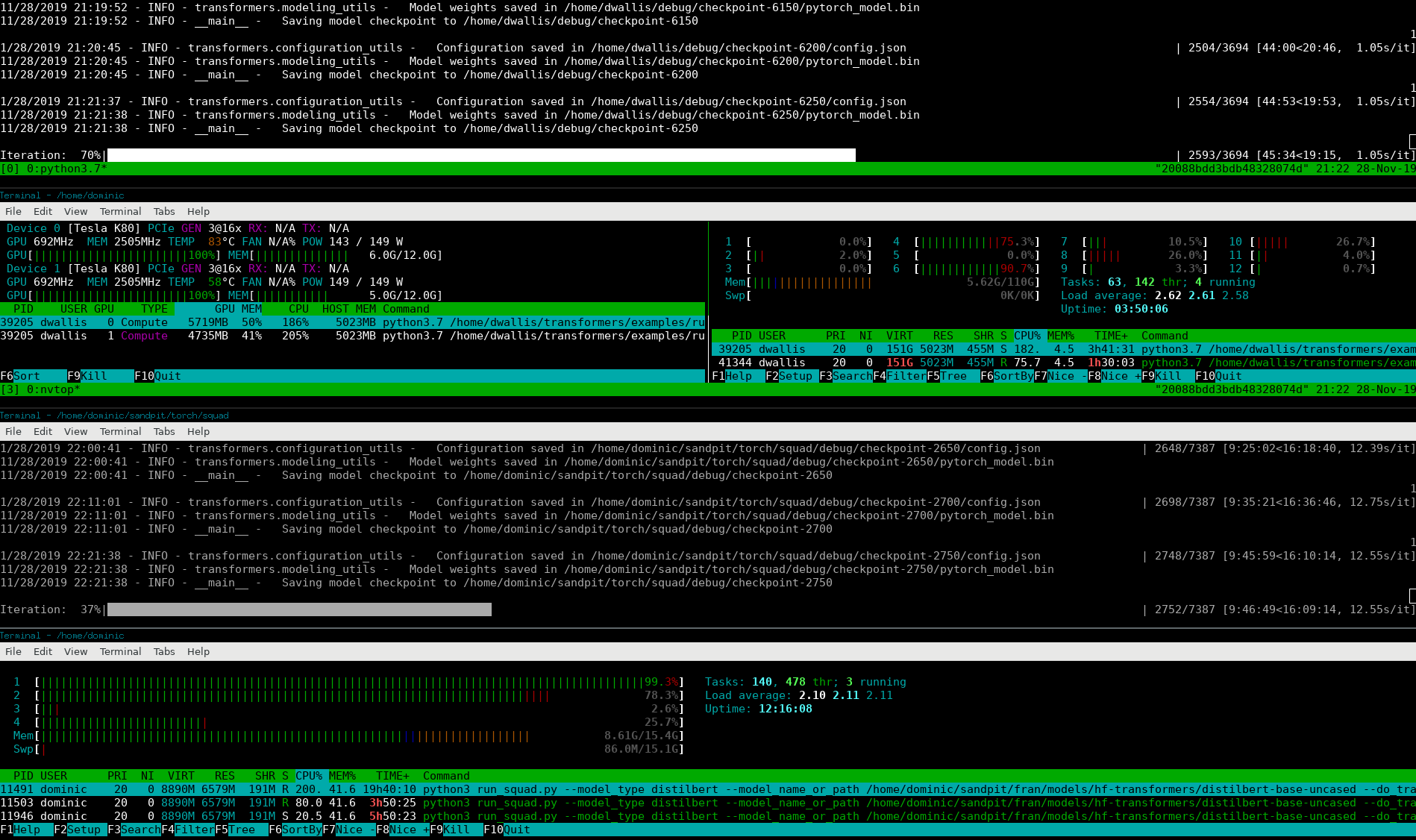 The four stacked terminals are:
The four stacked terminals are:
- program running on the cloud.
- nvtop and htop side-by-side on the cloud.
- program running on the laptop.
- htop on the laptop.
The cloud is on the second epoch, while the laptop is on the first.
Status > 2hours
It’s been a little over two hours. The results an in! They are … 🥁 🥁 🥁
Results: { 'exact': 76.5279091769158,
'f1': 84.93796320646177,
...Celebratory dance 💃
Celebratory dance concluded 👨💻
These results are 1.5 percentage points poorer than those advertised in the blog (78.1 EM and 86.2 F1). But, for a first ever run, I can live with that.
Now the problem of how to get the model…
All the checkpoints and the final input are in debug. Getting the model is a little tricky. I’m using sftp but it is super laggy (I never remember the syntax of scp). I’d like to get the intermediate checkpoints too, to see how the training evolved. Not sure how possible that will be.
…
I have managed to retrieve the final model, and related files.
The complete debug folder with all checkpoints came in at 37 GBs (du -h debug).
There is no chance of downloading it with these speeds.
Time to delete my machine and go home!